
Давай поговорим о комфорте при работе с кодом.
Мы с вами большую часть рабочего дня работаем с кодом.
И на самом деле мы больше читаем код чем пишем.
Важно чтоб код был понятный.
Так получилось что мы с вами люди.
Даниэль Канеман описывает мышление человека как работу 2х систем.
Система 1 срабатывает автоматически и очень быстро, не тратит ресурсы. Система 1 распознает текст на родном языке, классифицирует знакомые объекты, как яблоко или стул и достает из памяти понимание паттерна, когда вы видите слово singleton или метод sharedInstance().
Система 2 выделяет внимание, необходимое для сознательных умственных усилий и сложных вычислений. Система 2 потребляем много ресурсов.
Рядом с 2мя системами у человека есть 2 памяти: быстрая и долгосрочная.
Быстрая память похожа на дырявый стек. В этом стеке от 4х до 7ми слотов. Когда стек переполняется нижняя мысль просто выпадает на пол.
Долгосрочная память ненадежна и медленна. Долгосрочная память не участвует в процессе мышления. Она лишь служит свалкой знаний и опыта в которой сложно что-то найти, дорого читать и очень трудно записать.
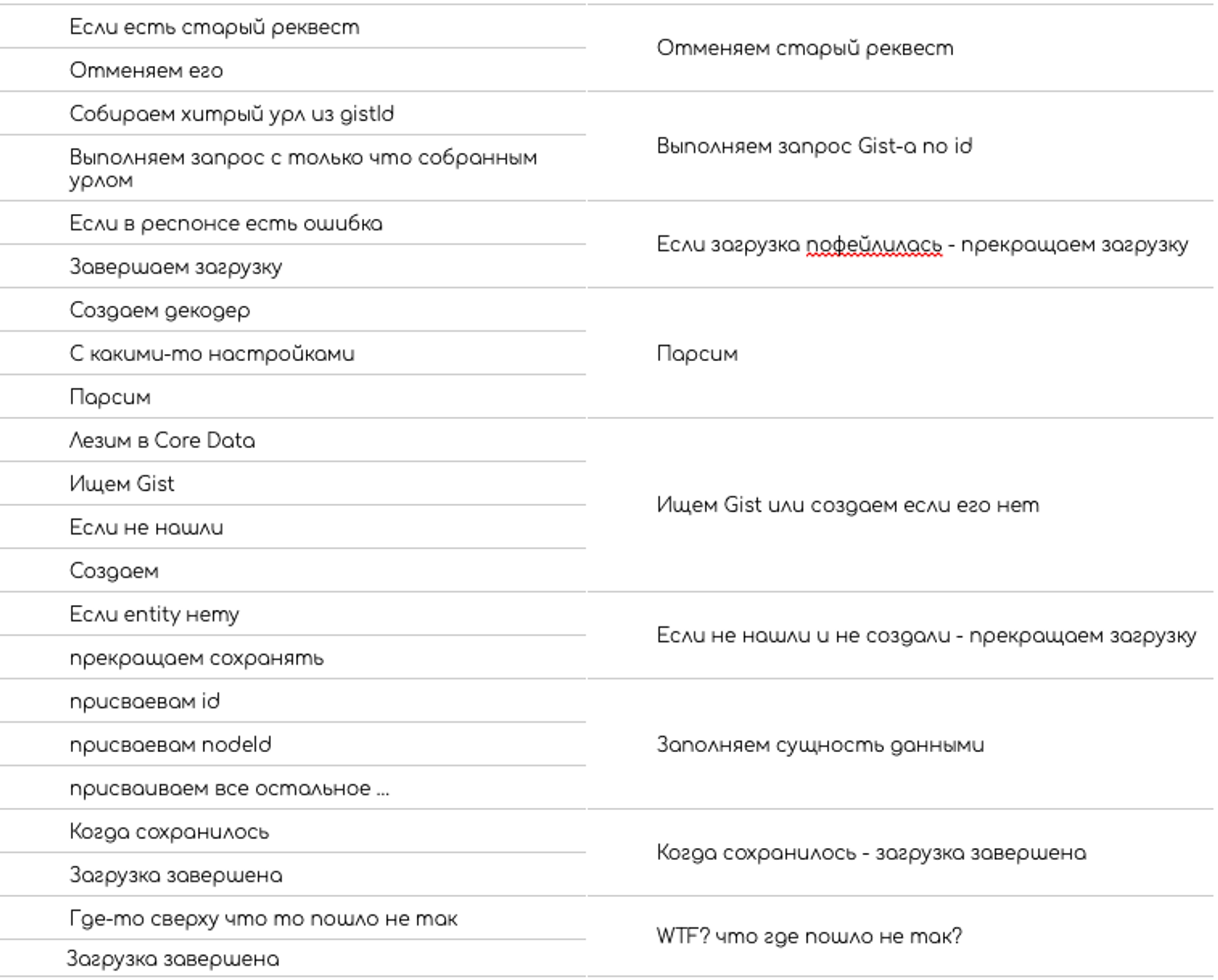
Чтобы разобраться в сложном алгоритме, программист читает кусок кода. Этот кусок занимает всего пару тройку мыслей, классифицирует ее и сжимает до одной или соединяет с уже имеющийся в стеке мыслью.
Потом переходит к следующему кусочку. Так большая структура может поместится в 4–7ми мыслях.
Читает код Система 1. Прочитанный код выражается в категориях знакомых Системе 1, она на достаточно низком уровне, это информация о переменных, методах, классах и их названиях, о том какие операции производятся с переменными, какие методы вызываются.
Примерно так я читал код одного из своих старых тестовых заданий.

После прочтения Система 1 передает прочитанную информацию Системе 2.
Система 2 сжимает переданную информацию в одну мысль. Мысль описывает то что делает прочитанный кусок кода.
Система 1 может сопоставить кусок кода с мыслью уже содержащийся в рабочей памяти, но не может самостоятельно сжать похожий кусок в похожую мысль, это уже работа Системы 2. Эта работа расходует ресурсы.
Сформировав мысль с описанием того что делает кусок кода, Система 2 очищает из рабочей памяти детали из которых эта мысль была сформирована и ищет следующий кусок который нужно прочесть.
Что может пойти не так?
Быстрая память — дырявый стек. Если ее переполнить, старые мысли вывалятся на пол. Их придется думать заново.
Запутанный код будет прочитан кусочками слишком маленькими для формирования понимания того что он делает. Тогда в быструю память будут складываться промежуточные этапы сжатия информации о том что код делает. Это расходует ресурсы.
Код может быть написан таким образом, что Система 1 будет отдавать ошибочные оценки, категории и опыт. Тогда Система 2 потратит больше ресурсов на изменение информации которую переделал Система 1.
Заботливый код помогает подготовить сложную и массивную логику программы к сжатию в понятные программисту идеи и категории, и складыванию в маленькую быструю память.
Как это сделать?
Уменьшить количество операция сжатия.
Уменьшить стоимость каждой операции сжатия.
И тут в чат врываются книжки Дядюшки Боба, Макконнелла и других прекрасных авторов.
Если перечитать знакомую книжку про паттерны, архитектуры или чистоту кода с оглядкой на теорию мистера Канемана, будет понятней зачем все это нужно и почему оно такое.
Если не на долго выключить зануду, то с некоторыми допущениями можно сказать что все полезные практики про одно и то-же.
Это разные способы уменьшить количество операция сжатия и стоимость каждой операции сжатия, во время чтения кода.
Огромный набор паттернов проектирования - должны стать набором мыслей которыми может оперировать Система 1.
Если ты видишь в коде FooBarFactory, то не задумываясь понимаешь, что эта фигня умеет порождать какие-то FooBar-ы.
Все эти бесчисленные архитектуры преследуют ту-же цель.
Если ты видишь классы, имена которых заканчиваются на View и ViewModel, то непроизвольно сделаешь вывод что тут MVVM и сделаешь несколько предположений о том как эти классы взаимодействуют не читая их код.
Легкий для чтения код:
- Содержит названия, по которым Система 1 бесплатно достает нужные понятия и опыт.
- Структурирован понятным читателю образом. Избавляет от необходимости сначала разобраться в структуре.
- Соотносится 1к1 с предметной областью.
Тяжелый для чтения код:
- Содержит названия по которым Система 1 достает ошибочные понятия.
- Содержит слишком много состояний, которое вываливаются из быстрой памяти.
Тяжелый для чтения код:
- Содержит неявные и ненужные зависимости. Зависимости нужно отдельно вычитывать, сжимать и упаковывать в быструю память.
- Содержит незнакомую структуру. На чтение и понимание структуры расходуются операции сжатия и дорогая быстрая память.
Знакомая архитектура лучше незнакомой.
Программист читая код работает с понятиями из 3х предметных областей.
- Предметная область приложения.
- Термины и понятия языка программирования, используемых фреймворков.
- Термины и понятия архитектуры программы и конструкций используемых на прикладном уровне.
Предметная область приложения — самая важная и интересная часть. Ради нее пишется программа.
Язык и фреймворки — уже знакомы программисту. С опытом эта часть расходует все меньше и меньше ресурсов.
Архитектура приложения каждый раз отличается. В ней нужно разбираться.
Обман в коде — несоответствие названия содержанию.
Встретив такой кусок читатель тратит дополнительные слоты в быстрой памяти на согласование названия с содержанием.
Так происходит каждый раз, когда встречается обманывающее название.
Самый распространенный пример обмана в коде - это когда класс называется так как компонент из какой-то популярной архитектуры, но при этом делает что-то что не связанно с его зоной ответственности в той самой архитектуре, из которой заимствовано название.
Например ViewModel, который ходит в сеть.
Тот кто знаком с MVVM в подлёдную очередь пойдет искать сетевой запрос в ViewModel.
Или сингтон, для которого оставили возможность создать несколько инстансов.
Каждое состояние и каждая зависимость — отдельная мысль, которую нужно хранить в памяти. Если их много, то они будут выпадать из памяти и каждый раз придется заново расходовать ресурс на чтение и удержание их в голове.
Если зависимость или состояние неявные, не задекларированы в интерфейсе, то ресурс каждый раз тратится еще и на поиск.
Каждый раз выпавшее из головы состояние влияет на чтение следующих кусочков. Без находящийся в памяти информации о состояниях программист может принять ошибочное решение или неверно трактовать прочитанный кусок.
Используй общепринятые архитектуры.
Используй знакомые подходы.
Используй готовые решения.
Соблюдай конвенции о именовании.
Уменьши количество состояний.
Уменьши количество зависимостей.
 Михаил Куренков
Михаил Куренков