

Архив недели @yatsinar
Понедельник
Всем привет👋, на этой неделе с вами @yatsinar, Lead Android Developer из Revolut
План на неделю примерно такой:
Пн: про меня, Револют и финтех
Вт: System Design и T-shape инжинирингСр: Толстые клиенты
Чт: Opensource
Пт: Тестирование, TDD/ TLD
Сб: Прод(же|у)ктоунерство и 10x инженеры
Вс: День шкур неубитых медведей aka фантиков aka золотых наручниках или по простому опционов
Начнём со знакомства. Как уже говорил, я работаю в Revolut, на данный момент тут уже 3.5 года, последние 2 из которых на проекте Wealth & Trading.
Ещё я полтора года уже как понаехавший в Туманный Альбион из Петербурга. Кстати передаю привет проповедникам этого стереотипа, после Питера тут ощущается как на курорте.
Андроид разработкой занялся в ~2011 году чисто случайно. Тогда, на первом курсе Института Тёмной Магии и Оккультизма лазал по всяким стартаперским тусам и наткнулся на ребят которым была нужен бесплатный разраб для приложения к умным розеткам и блютус брелкам. Так и завертелось.
Какой то полной определенности что вот это точно моё тогда не было; где то через год в каком то баре договорился сделать лендинг какому то мамкиному бизнесмену. Помню тогда две ночи в поезде Спб-Екатеринбург читал методичку как делать сайты на Джумле
Когда в 2014 был уже довольно давно с Андроидом, всё равно не отказался попробовать JS когда в компании в которой я тогда работал закончились проекты на мобилки.
Компания пилила ПО для внутренних нужд РЖД, (как потом оказалось последняя каждый год под конец квартала заказывали переделку этой системы, пилила бюджет и на 1/100 нанимала аутсорс контору через посредников)
Переделанный проект в декабре радостно демонстрировался чиновникам организовавшим сей распил, и выделивших на это бюджеты, и топам контор посредников которым эти тендеры достались, и которые отчехляли откаты чиновникам
После проект отправлялся пылиться в государственных приватных кодовых репозиториях, до следующего сентября/ноября в которых опять уже декабрь скоро, а бюджет еще не освоен и можно делать заново
На этом моё знакомство с JS и закончилось)
Была ещё куча странных активностей на всяких инвесторских форумах, где за еду пилил разные прототипы всяким Зеленоградским Стивам Джобсам (лайк кто знает куда отсылка)
В какой то момент даже Unity и геймдев поковырял.
Но где-то года с 2015-го всё стабилизировалось и я продолжил ток на одном Андроиде
Продолжая свою историю, в 2015 ушёл из первой аутсорсовой компании во вторую аутсорсовую. Тогда еще особых предпочтений по продуктовости не было, хотелось ЗП и побольше движа.
Ушёл в Омнигон, который делал приложения под спортивные компании на заказ, купил меня узкой направленностью проектов, американскими заказчиками и потенциальными командировками.
И тут мне прям на второй неделе предлагают "В LA го?". А я на тот момент жил в студ общаге в Питере, в комнате на четверых, писал диплом и пил пиво.
А через месяц я получал визу в посольстве, через еще неделю с чемоданом выехал из общаги в аэропорт, и через 20 часов заселился в king suit в 4х звездочный Hyatt в LA за счёт заказчика на шесть недель.
Немного стыдно, что ничё особо полезного разработанного я с этого проекта даже вспомнить не могу. Крестик, помню, добавил в меню просмотра новости. Но это была единственная такого рода командировка к сожалению).
Проработал там почти два года и помню как было довольно грустно и немного страшно уходить. К компании претензий было ровно ноль. Команда супер, проекты интересные. Они даже помнится сделали встречный оффер (я через два года уже не только крестики делал всё-таки).
Но очень в тот момент хотелось попробовать продуктовую разработку. Делать что-то чем пользуешься сам. И тогда почему-то очень хотелось в финтех.
Револют нашёл чисто случайно. Вообще пытался связаться с Тинькофф, который тогда только открывал в Питере офис, но HR не отвечали неделями и пару месяцев не было никаких подвижек.
Я тогда решил зайти сбоку и нашёл человека, который знает человека, который там работает. На что он мне сказал "а зачем тебе Тинькофф, оттуда все в Револют уходят". Загуглил что за зверь, понравилось. Связался и весь процесс занял наверное две недели.
Подозрительно было, что офиса в Питере еще не было, и они сказали "ну сначала месяц в Мск, потом недельку другую удаленно, может, а там глядишь и снимем".
Свежеснятый питерский офис кстати навсегда в моём сердце) В первые месяцы там было буквально 10 человек. Покурить выходили все вместе. Обедать вместе. Это какой то особенный, непревзойденный, подвид тимбилдинга - быть первыми в офисе. Если где-то предлагают - не отказывайтесь)
Плавно переходим к мыслям про Револют, стартапы в целом и финтех в частности. Постараюсь хотя бы не повторять предыдущих коллег, кто уже тут вещал, а то там уже предложили канал в "Мобильный разработчик Револют" переименовать).
Начну с культуры и процессов, и чем они отличаться от других IT компаний.
Вообще почти во всех компаниях "культурный фреймворк" можно довольно отчетливо отнести в одну из двух корзин: Исполнительный и Инновационный.
Финтех зверь крайне зарегулированный и как бы стартапы не изворачивались - на инновациях ехать крайне сложно. В финтехе более подходит Исполнительный фрейморвк. Вижу цель, не вижу преград.
На него сильно влияет именно зарегулированность бизнеса, и все принципы и процессы формируются там сверху и как правило спускаются в область разработки.
Тут все пытаются get shit done. Shit этот, как водится, если покопаться, давно задокументирован, зарегулирован и почти наверняка уже кем-то done. Все процессы которые тут могут показаться инновационными (типа agile) часто обусловлены неопытностью в именно этой конкретной сфере.
В первую неделю выкатываем новую фичу, во вторую регулятор говорит что так нельзя, в третью переделываем. Agile тут нужен для ускорения этих итераций.
У нас кстати, конкретно в трейдинге, есть одна забавная проблема - по европейским меркам мы огромны и набрали юзеров слишком быстро, и олдскульные регуляторы крайне недоверчиво относятся к каждой нашей микрофиче, и иногда согласовать даже что-то простое - целый челленж.
А каких-то принципиальных, фундаментальных инноваций, лично мне пока видеть не приходилось. Ходят слухи, где-то в области крипты ещё можно что-то изобрести, хотя и там все продукты - это калька существующих финансовых проектов.
Тип оп здорово, Coinbase - инновационный стартап даёт проценты на биткоин вклады. Инновации? Не оч, вся схема займов уже давно отработана на фиате. Нужно только положить на другой вид ассетов, посчитать риски, и покрыть их как-то премиумами.
Маленькое раздолье на инновации остаётся в области дизайна и UX. Но исполнительный подход чаще всего затрагивает всю компанию и все процессы.
И покуда бизнес строится по принципу сделать как разрешают ток хорошо, то и на разработку дизайнов, UX и приложений давят такие же принципы.
Сделать сразу и нормально, может даже как у кого-то. Гугловых ресурсов ресерчить тысячи идей и хоронить 100 проектов в год в финтехе нету. Но это в целом для любого стартапа верно.
Миллионы про которые говорят в новостях в огромных количествах уходят на обеспечении финансовой деятельности, коллатеризацию, получение лицензий и прочие пейроллы.
Проблема может быть только в том, что "сделать хорошо" - крайне субъективное понятие. А часто ещё и политизированное. Приняли в разработку твою идею а не коллеги, получил политикал пойнтс.
В итоге иногда сотрудники борются за поинты, а не чтобы юзеру удобно было. Оттачивают навыки питчинга идей, а не ресерча аналитики.
Но в целом у нас данным и ресерчам уделяют огромное внимание. Данные аналитики - единственный аргумент который может перекрыть мнение стейкхолдеров.
Только может AB тесты - энтити нон грата. Считается, что если ПО не может выбрать из двух вариантов UI, то грош цена такому ПО.
По итогу не могу сказать что это плохо. Финтех - это просто компании которым нужно зарабатывать деньги, и сделать это как можно быстрей. Возможно даже в этой области требования гораздо более серьезные к заработку.
Если Uber не может за десять лет начать зарабатывать, это одно, если банк - то это уже другое. Пацаны в баре не поймут.
Вообще надеюсь Револют и финтех в целом из Execution Culture когда нибудь проэволюционирует в Innovative Culture. Но явно не раньше того, как начнёт зарабатывать.
Небольшая рекламная интеграция: спешите попасть на podlodka.io/droidcrew, новый топовый формат, почти сам вписался вещать, но в 8 утра ничего членораздельного рассказать не смогу к сожалению
Ну и в завершении первого дня злободневная тема: working culture, переработки, сокращения и увольнения.
Внезапно лайфак как быстро чекнуть в каком графике работает компания - это посмотреть popular times офиса в google maps.
Угадайте, где финтех (ЗЫ это кстати не Револют):
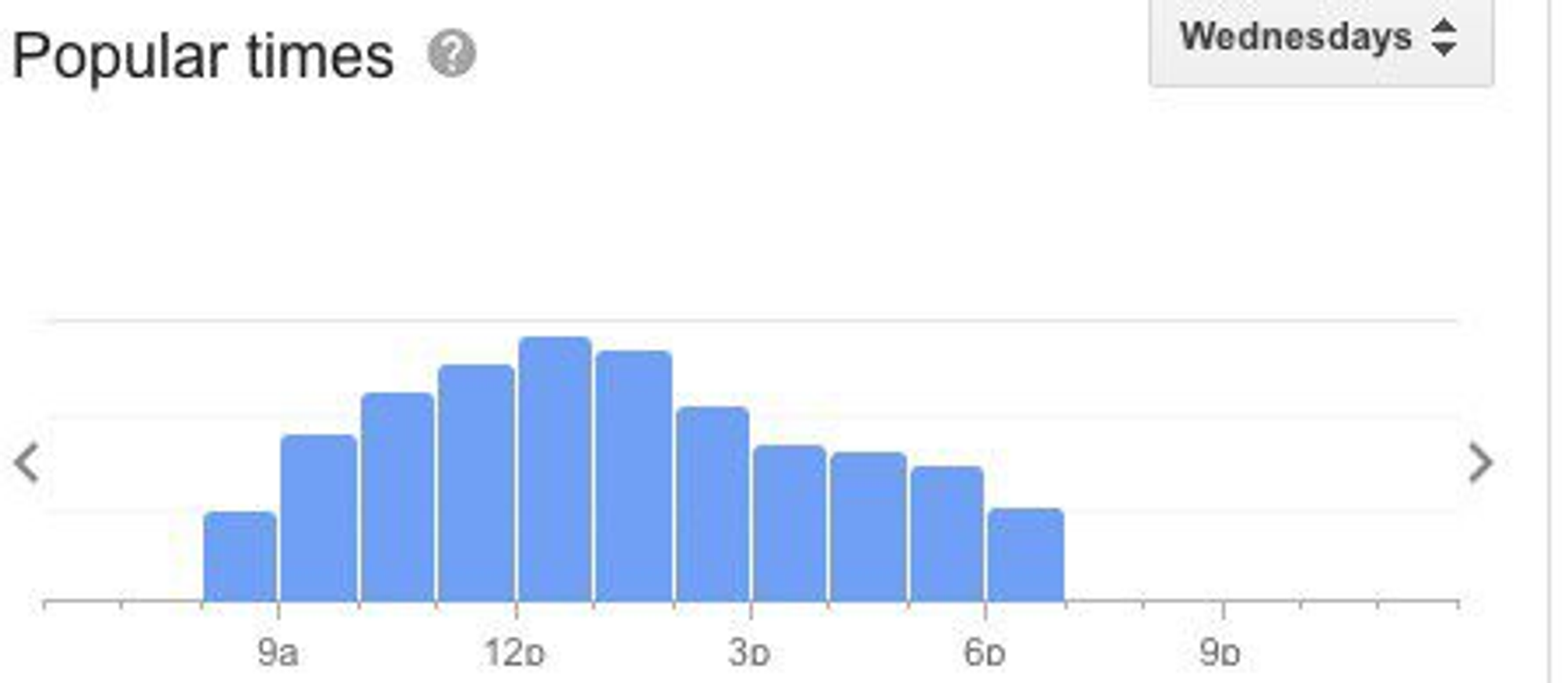
По переработкам, моё личное мнение, что у нас нет ничего прям критически выделяющегося в IT или финтехе.
Они, вообще, наверное, скорее есть, чем нет. Очень много сотрудников всё ещё сидит в офисе в 9. Причины у всех свои, но чаще позитивные: интересная задача/фича, просто нравится работа и своя деятельность.
Мы тут не шахту капаем, у многих работа - это оплачиваемое хобби, если это не так, то грустно будет и с фиксированным графиком.
Ну и мотивация: лично я, и думаю многие другие относятся к успеху компании как к своему собственному, включая финансовый.
Из негативных причин бывают классические неверно оцененные задачи. Либо сроки спущенные сверху, но последнее все-таки нечасто бывает.
Стоит отметить, что тут есть разработчики, с семьями и детьми, которые вполне себе успешно успевают справляться со всем что нужно в стандартные 8 часов и быстрее и никто их за это не упрекает.
Нередки ситуации когда всё готово, и остается пара свободных дней в конце спринта, "копать отседова и до полуночи, и фару на лоб" никогда не скажут.
С нагрузкой вообще помогает справляться WFH полиси, которая пока самая гибкая какую мне доводилось встречать. Формально есть некоторое правило что не больше одного дня в неделю, на практике его форсят только в крайних случаях.
Разработчики приходят в офис когда удобно, уходят когда удобно. Отметки дней из дома в HR системе носят больше уведомительный характер. Кстати вся компания максимально бесшовно переехала на full remote во время короновируса.
Вообще, кстати, олд скульный финансовый сектор во всём мире довольно хорошо известны за свою агрессивную корпоративную культуру, где и уайт супремаси, и харасменты и абьюзинг.
В этом плане в финтехе ничего такого и близко нет, и тут гораздо спокойнее чем в классических финансовых организациях. И гораздо более похоже на IT компании.
А переработки есть и в других местах, в здравоохранении, полиции, не совсем понятно почему в целом гораздо более благополучный IT и финтех получают такое прицельное внимания прессы.
Про сокращения:
Сотни стартапов провели сокращения, Револют кажется единственный где сообразили сделать salary sacrifice schema. Многие в ней участвовали не по принуждению, а полноценно рассматривали это как инвестицию (втч и я).
Я кстати даже удивился, насколько большее количество людей закомитились. Из всех с кем я лично общался, ни у кого не было ощущения принуждения, как писали в медиа. По-крайней, мере у инженеров точно.
По итогу именно сокращений среди инженеров я лично вообще не знаю. Когда закрывают проекты/увольняют ПО, инженеров мы всегда распределяем.
British Airways, например, на минуточку, уволило и перенаняло несколько тысяч сотрудников под принуждением на пол ЗП, без опционов в замен. Моя медиа лента, конечно, заточена под финтех, но навскидку BA получил чуть ли не меньшую огласку.
viewfromthewing.com/british-airway…
Ну и напоследок немного инсайдерской инфы - Револют закрываться не собирается, ни с одного рынка мы тоже не уходим, как N26 из UK, из продуктов закрылись только пара нишевых штук типа консьерж сервиса. Ковидное падение довольно быстро отскачило на прежний уровень.
Вторник
System Design - как подростковый секс. Все о нём говорят, всех спрашивают, думают что у других он есть, и всем говорят, что сами занимаются. А как часто он у вас? 😊
Начну рассказывать про System Design, как это вообще может касаться мобильных разработчиков и зачем это вообще знать.
System Design вообще штука абстрактная и довольно всеобъемлющая. В общем и целом заключается в проектировании глобальной системы, клиентское приложение в которой это только финальная точка.
А глобальные системы в современном IT имеют некоторую тенденцию быть: distributed и event-driven. Вообще, они конечно все ещё довольно часто монолитные, и там есть свои нюансы.
Но лично я чаще всего встречал, что под System Design имеют ввиду именно понимание особенностей distributed и event-driven систем, и проектирование модулей/сервисов/клиентов именно в такой среде.
SD также покрывает и, например, построение пайплайнов нейросетей, хранилищ данных (warehousing), алгоритмы децентрализации сетей, но клиентскую разработку именно эти области почти не затрагивают.
Факт распределенности системы на мобильного разработчика, как бы не хотелось этот факт инкапсулировать за простым гейтвеем, часто протекает в серверном API, с которым приходится работать.
API или поведение какого-то запроса иногда может выглядеть странно и непонятно, особенно если не знать, что происходит за границей http библиотеки.
А иногда нужно полноценно принять участие в проектировании нового API и, возможно, даже повлиять на дизайн приложения, чтобы оно не пыталось идти против реалий системы.
Рассмотрим Eventual Consistency. Представьте, есть два с̶т̶у̶л̶а̶ запроса - один добавляет значение в массив, второй возвращает массив значений. Вы отправляете первый, получаете 200, зовёте второй, а там пусто.
Какого черта? Запрос чтения ушёл не в ту же реплику, что и запрос на запись. А система не гарантирует Read-Your-Writes Consistency. Значение там будет. Eventually.
И если экран отправки первого запроса отправляет юзера на экран второго, в котором предусмотрено, что данные появляются не сразу, и UI к этому готов (хотя-бы pull-to-refresh), поздравляю, вы великолепны, Eventual Consistency теперь часть UX.
Проблемы появляются, когда в дизайне - синхронно работающий флоу, а под капотом лежит асинхронная дистрибьютед система без строгих гарантий.
Если, например, в дизайне нужно показать следующий экран, сразу со списком из второго запроса, и UI там не предусматривает обновления данных, то Хьюстон у нас проблемы.
Мобильному разработчику как минимум стоит знать, какие гарантии даёт сервис, понимать что они значат, и как можно с ними жить. Например, написав поллинг запроса на том втором экране.
У нас был кейс, когда отсутсвие такой гарантии ломало красивую абстракцию дата слоя, потому что свежеприбывший пустой массив затирал предварительно сложенный в базу клиентский объект.
Такие проблемы можно решать, например, версионированием данных. Подходов много. Например, клиент перед запросом инкрементит локальную версию, и массив пришедший из устаревшей реплики будет иметь версию меньше.
Клиент такие данные может игнорить, считая свои более свежими и, например, запуская поллинг запросов, которые содержат устаревшие.
Eventual Consistency вообще может дико звучать в контексте финансовых приложений, которые, казалось бы, ОБЯЗАНЫ работать синхронно и, видимо, падать при первых же инконсистентностях в данных.
Но всё не так страшно, покуда эти данные используются только для отображения и где-то существует мастер версия. Все финансовые операции, разумеется, будут проводиться по мастер версии.
Коротенький тред про probability structures.
Открываете например профиль рандомного dude на Twitter. А там Follows You. Открываете список following: вас нету.
Втф? Тут могу ток гадать, но, вероятно, под капотом Follows You работает какой-то вероятностный алгоритм или структура, например Bloom Filter. Он, по элементу может сказать: definitely is not in the set, или maybe in the set.
Definitely is not in the set не может отметить того, кто вас фолловит, а maybe in the set может, но с вероятностью ошибки. В финансовых бэкендах пока таких оптимизационных трюков не встречал, и на клиентах тут наерн особо ничего и не сделать.
Ток может предложить поменять лейбл Follows You, на Definitely Not Follows You, или Maybe Follows You но дизайнер вряд-ли согласится)
Но на System Design интервью такое оч часто попадается на проектировании API высоконагруженной системы где maybe in the set может быть удовлетворительным ответом.
Идём дальше по кейсам. Есть у вас скажем POST запрос, на отправку денег. Зовёте, получаете в ответ 500. Радостно повторяете его. Потом дергаете запрос на баланс, и там видно, что списалось два раза.
Что произошло? 500 пришедший с сервера говорит, что чет у них там крашнулось. Крашнуться мог просто сервис гейтвей на возврате ответа, успев при этом передать запрос на трансфер дальше. Второй запрос полноправно списал деньги второй раз. Потому что запрос был не идемпотентный.
Про идемпотентность чрезвычайно мало пишут и говорят в контексте клиентской разработки. Разработчик часто может увидеть непонятный недокументированный параметр в API с типом String и не понять что туда передать.
Хорошо если он назван "idempotencyKey" и можно хотя бы загуглить что за зверь такой, но я был свидетелем поля с немногословным именем "op". На бэкенде, видимо, была посимвольная тарификация.
Идемпотентность - один из корнер стоунов дистрибьютед систем. И очень полезно знать где и как её применять. По простому она значит, что операция меняет стейт только один раз. i++ - неидемпотентная операция, compareAndSet(expected, new) - идемпотентная.
Если бы в упомянутый выше запрос выставили "op" = "1", то ретраи не несли бы никого эффекта и деньги бы списались один раз.
Бонус ещё в том, что клиент в полном праве генерировать "op" самостоятельно. Главное следить что он уникален и соответсвует пользовательской операции. Можно просто какой нибудь UUID.random() использовать и следить, чтобы он не менялся на дистанции одного пользовательского флоу.
В распределенных системах, где один запрос может прогоняться через десятки микросервисов, safe-retry - это жизненно необходимая характеристика, чтобы иметь возможность на каждом узле повторить операцию, если произошел сбой, а не ложить всю цепочку.
Почти все платежные провайдеры содержат такой параметр в API, и пометить все запросы ключем, чтобы гарантировать safe-retry всех звеньев цепочки микросервисов, может только источник этой цепи, то есть в нашем случае - приложение.
Видел некоторую вариацию, где такой ключ создаётся бэкендом и клиент его сначала запрашивает, а потом выставляет в запросы. Чаще всего в таких маневрах смысла мало. Уникальность UUID достаточна для таких целей, а сервер легко может заджойнить ключ с айди юзера.
Ну и последний на сегодня кейс про CQRS - вы видите POST запрос на создание какой нибудь сущности, в ответе которого не возвращается созданный объект, только id. Везде возвращается, а вот тут нет.
И теперь надо писать дополнительный запрос, для забора сущности по id сразу после создания, и экран который создавал теперь должен еще и удостоверится что сущность создалась.
Тут у нас опять два стула. Можно написать, а можно попросить бэкендера добавить объект в ответ. И многие не моргнув согласятся.
А через пару месяцев развития системы выяснится, что микросервис принимающий запрос не может вернуть объект синхронно без костылей, потому что всю систему рефакторят на event sourcing.
А event sourcing это как EventBus - микросервис инициирует создания объекта, со сгенеренным id, и подписываете на ивент завершения создания.
Самим созданием займется вообще кто-то другой. Или third party сервис. И это невозможно дождаться в одной сессии POST запроса, которому пришлось бы блокирующе ждать события, чтобы отдать тело.
Парадигма CQRS (Command Query Responsibility Separation) разделяет запросы на создание сущностей, commands и их последующий querying. И это закономерно утекает на конечного потребителя API - клиентское приложение.
Поэтому и два запроса - один сабмитит команду создания, второй поллит пока не появится объект. При наличии какого-нибудь сокета можно просто ждать ивент с сервера.
Кстати, после того первый запрос на создание выполнится, и клиент закверит созданный объект по id - там по прежнему может быть 404 и eventual consistency если сервер не гарантирует Read-Your-Writes.
CQRS очень часто упоминается при service-to-service взаимодействии, но к сожалению, гораздо реже в контексте клиентской разработки. Хотя концепция довольно полезная, и в целом, таким же принципом можно пользоваться при любых write операциях.
Разделять в каком нибудь условном презентере отправку параметров создания и ожидание результата. Это будет полезным мувом в каком нибудь MVP, если архитектура уже само по себе не event-driven.
Как пример, на Rx doAction(params) был бы Completable и подписывался бы по пользовательскому клику. Ожидание результата подписывалось бы всегда на onAttach как observe(): Observable<Result> и если результат появился в свернутом состоянии, при развороте он доставится в презентер.
Сабмит параметров операция синхронная, вся асинхронщина легко переживает пересоздания презентера в дата слое. Под капотом на дата слое может быть запись в базу, поллинг запроса или ожидание ивента в сокете. Презентейш слою уже +- всё-равно.
Опрос в начале дня показал, что 66% ждут своего часа)
Ну что, у кого нибудь в конце дня есть мысль "Тюю, так это оказывается был систем дизайн, тогда у меня уже всё было"
Воу. Для кого я про редакс на мобилках пятый год рассказываю?)) CQRS FTW twitter.com/mobileunderhoo…
Два чая этому господину) twitter.com/DAlooG/status/…
Среда
Сегодня поговорим об оффлайн моде.
Штука эта для многих, особенно среди менеджмента, может звучать легко, как будто где-то в плей сторе есть опция "чтобы было норм без сети", а мы такие жуки уже третий релиз её забываем отметить.
На деле есть десятки разных подходов, начиная от кэширования респонзов по урлам, заканчивая полной репликацией в базе данных.
Расскажу немного, про разные варианты, и как сделано у нас.
Я вообще не особо понимал, зачем банковскому приложению offline mode, пока не переехал из Питера в Лондон. Сети тут конечно полный треш, особенно в метро.
И, на самом деле, у нас наверное единственное банковское приложение, в котором он есть. По крайней мере я не встречал чтобы без сети можно было хотя бы посмотреть чё там с балансом.
Может они делали какой-то юзер ресерч и пришли к выводу что оффлайн не нужен. Ну вы поняли). "Опрос проведённый в интернете показал что 100% юзеров имеют доступ к интернету".
Но у нас это было персональным желанием важных стейкхолдеров.
Начнём с того как у нас не сделано. Например, через кэширование ответов. Штука крайне примитивная. Если вы запрашиваете список транзакций, он, конечно, закэшируется, но транзакцию открыть будет нельзя, если она запрашивается другим урлом.
Так же закономерно абсолютно не трекаются связи между объектами, если транзакция по урлу пришла не такая как в списке - кэш запроса списка это не поменяет.
OkHttp еще кстати не поддерживают шифрование в кэшированных ответах. Видел пропоузал в пятую версию, сейчас, на минуточку третья. Внукам покажу. Даже для 304 Not-Modified пришлось руками с отдельным стораджем работать.
В целом рабочий способ на приложения в которых один экран - один запрос. Но здесь вам не там.
Теперь про наш сетапчик. Он наверное, довольно средний по сложности. Поддерживаем только read, write оффлайн пока нет. База - стоковый Sqlite с шифрованием и Room. Но даже при таком раскладе начинают вылазить забавные моменты. Тут релевантно будет больше для Android
Например теперь нужно синхронизировать реляционные зависимости с бэкендом. Там чаще всего примитивщина типа один wallet - одна currency - много transactions.
Немного изворачиваться приходится из-за ограничений Sqlite, он крайне примитивен.
Банальный Upsert судя по таймлайну версий станет широко доступен лет через пять. Insert(OnConflict.Replace) вам радостно грохнет каскадом все форейн записи. Приходится делать двойную транзакцию Insert(OnConflict.Ignore) / Update.
Sqlite ещё не умеет в полиморфизм. На эт есть древний хак - держать поля чайлд в отдельной колонке таблицы названой именем это чайлда. Можно через Embedded в Room.
Миграции данных на лонг терм проектах это мастхэв. Причем не только схемы, а именно данных. Drop Table сильно расстраивал бэк когда в день релиза новая версия клиента ломилась выгружать себе все данные.
Сильно выручают инструменты тестирования Room. Создать в тесте базу версии N, вставить записи, прогнать миграцию до N+1 - займет строчек десять, не считая декларации самих записей.
Читать данные из базы Андроид гайдлайны советуют прям на мейнтреде. Эт прям оочень спорное утверждение. Даже с индексацией, запрос с парой джойнов на поюзанных лоу левел девайсах подползает по времени к 300ms, что сопоставимо с запросом в сеть. У нас чтение/запись всегда на IO.
Строгого требования кстати складывать именно в базу у нас нет, для прототипов можно обойтись мемори кешом, для MVP или просто проектов, где гарантированно не оч много данных - shared pref стораджом, который тоже шифрован.
Вообще из позитивного - это всё прокачивает скилл SQL до примерно уровня Junior Data Analyst, на случай если хочется свернуть с зелёной дороги)
Далее встаёт вопрос, как приоритизировать источники данных, не ответив на который централизованно для всего приложения, можно получить довольно ощутимую разножопицу. Тут есть две стратегии: cache-first и network-first.
Network-first по сути продолжает работать как обычное онлайн приложение и только в случае ошибок сети фоллбэчится на базу или кэш.
Из плюсов network-first - это простота реализации UI, у которого чаще всего есть только один вид транзишенов - от пустоты к данным. Из минусов - он ощущается сильно медленней для юзера.
Cache-first - всегда показывает данные сначала из кеша, потом лезет в сеть, и обновляет из на UI. Такое сложней поддерживать, потому что теперь сценарий обновления данных на экране появляется почти по дефолту.
Но это гораздо более быстрый UX. И кстати, превентивная прогрузка данных упомянутая ранее, в целом имеет смысл только при cache-first.
А для транзишенов между старыми/свежими данными есть огромная куча подходов, от стандартного animateLayoutChanges до DiffUtill в RecyclerView.
Этот подход мы кстати и используем. Тут на руку сыграло решение делать каждый экран на RV, поэтому всё работает автоматом.
Может и про нормализацию стейта будет? twitter.com/mobileunderhoo…
О кстати да, чуть не забыл, нормализация стейта. Если очень грубо, это валидация того, что все записи хранятся один раз и имеют single point of truth. twitter.com/DAlooG/status/…
То есть положим есть запрос на трейдинговое портфолио, в которое вложены все холдинги юзера. И еще каждый холдинг можно отдельно запросить по id.
Соответственно для холдингов source of truth - локально - это таблица holdings. Если запрос holdingById возвращает что-то сверх того, что приходит в Portfolio, можно положить эти излишки в holding_details для удобства.
И когда мы получаем Portfolio из сети - мы обновляем в таблице portfolios само портфолио, и дополнительно в отдельную таблицу пишем все nested holdings.
При чтении из базы чтобы собрать полное доменное Portfolio - нам надо опять же прочитать Portfolio из portfolios и все его holdings из таблицы holdings.
Если гугл мне не изменяет, в веб фронтендовом Редаксе есть библиотеки, которые это делают в почти автоматическом режиме, разбирая респонзы по размеченным схемам.
Не уверен насчет того насколько автоматом это происходит в Android Redux фреймворках, но мы такой propagation of truth на дата слое делаем руками.
А Rx позволяет из дата слоя торчать наружу условными observePortfolio(): Observable<Portfolio> и observeHolding(id: id): Observable<Holding>, которые все обновления будут эмитить всем подписчикам.
Оффлайн мод сам по себе уже достаточно контрибьютит в толстоту дата слоя на клиенте, но у нас ещё один гость в студии: клиентская логика .
Расскажу сразу на реальном примере, где было принято решение держать вычисления на клиенте, это расчёт текущего баланса трейдингового портфолио.
Для его расчетов в выбранной валюте, скажем в £, нам понадобится: текущие цены всех холдингов в USD. Курс USD-GBP пары, чтобы перевести все холдинги и их цены в GBP. Список всех холдингов с количеством.
Курсы валют нужно поллить. Цены стоков тоже нужно поллить. Список холдингов +- статичная инфа, но что-то может произойти в фоне, типа исполнение ордера, поэтому там тоже на всякий случай стоит сделать реактивно.
Перемножить одно на другое, сложить с третьим задача в целом элементарная, это даже не деревья вертеть.
Попутно нужно только учесть кучу логики связанной с хождением денег и превращением их в стоки и обратно. Например pending order прибавлять еще не надо, а unsettled cash assets надо.
Опять нужно думать, согласовывать с бэкендом логику и зачем это всё на клиенте вообще, положите просто balance в get portfolio запрос.
Тут всплывают некоторые особенности микросервисной архитектуры. Цены на стоки лежат в одном микросервисе, пары валют в другом, портфолио пользователя в третьем.
Если мы хотим balancePortfolio - получать сразу внутри Portfolio, этому сервису придётся ходить в три других чтобы отдать всю инфу.
Плюс, мы уже показываем на экране цены стоков. То есть поллим их отдельно напрямую из сервиса цен. Если мы будем баланс запрашивать через посредника, он будет перманентно отставать от цен на экране просто за счет более длинного пути запроса.
И если мы будем поллить этот мега гейтвей, он станет бутылочным горлышком всей системы.
Оно конечно всё легко горизонтально масштабируется, и тут мне сложно судить, но есть мысли, что такие боттлнеки чертовски дороги в лонгтерме, в плане оплаты всех этих инстансов, Амазон не просто так треть доходов с облаков имеет, и лучше спроектировать это дело пораспределенней.
Четверг
Сегодня поговорим про Open Source.
Само явление всегда считал безумно крутым, тысячи разрабов контрибьютят во что-то публичное, что может использовать кто угодно, где угодно.
Слышал мнение, что мол IT - мол единственная сфера, где такое возможно. Это конечно же не правда. Научный ресерч, фармакологические патенты (если забыть про
кощунственный patent expiry), финансовые/бизнес технологии и много других штук шарятся в очень похожем стиле.
Если рассматривать IT систему - огромное количество компонентов в ней будет написано в опенсорсе. БД на сервере, сам серверный фреймворк, сам сервер, тулзы для ивент-сурсинга, даже язык на котором сервер написан и компилятор, который его собирает.
В миллионах строк кода, которые обеспечивают функциональность всей системы, я не знаю насколько мизерная часть - это непосредственно проприетарный код.
Такая же ситуация в приложениях - вряд-ли вы сами пишете разбор http стрима, каждый раз когда в новой аппе нужно добавить загрузку. Вряд-ди вы сами пишете парсер json. И крайне маловероятно вы иcпользуете для этого не опенсорс библиотеку.
Тут конечно важно чувствовать грань между тем что должно быть заимпорчено, а что написано самостоятельно.
Грань эта будет сильно зависеть от горизонта жизни проекта и кодовой базы, от зрелости команды. Переизобретать даже самые простые компоненты, если у вас проект через год сдается и закрывается - не стоит.
На примерно 3 проекте обязательно сформируется core модуль с импортами с гитхаба, которые переезжают из проекта в проект. В какой то момент часть из них будет уже переписана локально. А чуть позже придут мысли это выложить на гитхаб. Круговорот и эволюция кода в природе прям)
3 года назад в нашей андроид аппе была по одной опенсорсной либке на любой чих. Диалог - либка, кастомный боттом шит - вторая либка, график - третья и так далее. С ростом довольно быстро приходило понимание, что вот уже проще поддерживать своё.
Реже стали происходить ситуации когда либка покрывает больше чем нужно, и чаще, когда меньше чем нужно.
У нас теперь почти всегда при разработке чего-то нового - это почти всегда делается самостоятельно в проекте. Кроме конечно фундаментальных штук типа Dagger / Rx / etc ну и может каких то очень хорошо абстрагированных и протестированных штук.
Например форматтер дат рождения у RedMadRobot взяли, там видно сколько усилий вложено, сколько эджкейсов отловлено. Я туда тогда даже однострочный PR запилил на какой-то новый кейс.
Но как выложить что-то своё, всегда преследовало какой-то ощущение что нахер мои поделки никому не нужны и либо что уже есть среди миллионов проектов на гитхабе, что-то что решает проблему. Или вообще проблема надуманная.
А вот настоящий эволюционный круговорот кода в природе в нашем проекте прошло пока только две либки, которые переехали на гитхаб, про которые и расскажу в отдельных тредах.
Расскажу про первую нашу библиотеку: RxData github.com/revolut-mobile…
Вчера мы говорили про оффлайн мод и приоритезацию источников данных. И про разножопицу, которая может быть в проекте, если заранее не договориться как делать.
А имея как входные данные БД + требование к оффлайну + Rx сделать можно сотней разных способов. И собственно изначально так и было.
Где-то выбор источника происходил в доменном слое, где-то в дата слое. Где-то был cache-first, где-то network-first и onErrorResume из БД.
Для оповещения множественных подписчиков где-то использовались Subject, а где-то его не было.
Вот всю эту ерунду мы и решили систематизировать и упаковать в библиотеку. Начали наверное с того, что решили, что выбор источника должен происходить в репозитории, а интеракторы и прочие презентеры париться не должны.
Но некоторые абстрактные данные о происходящем всё-таки нужны. В этом помог LCE паттерн. Эт по сути просто враппер класс, с loading: Boolean, и error: Exception?. Ну и content: T?. Получилась обертка, которую назвали Data(content | loading | error).
Теперь наши репозитории торчали наружу методами типа observePortfolio(): Observable<Data<Portfolio>>. Нужно было как-то обобщить имплементацию.
Через несколько итераций различных экстеншенов, билдеров и прочих фабрик пришли к последнему виду - финальный класс, который в конструкторе принимает лямбды доступа ко всем дата сорцам и расширяется только через декорирование этих лямбд.
Нарекли класс DataObservableDelegate или коротко DOD.
DOD принимает в себя лямбды чтения из памяти и стораджа, лямбды записи в память и сторадж и лямбду для сетевого запроса. Всё опционально. Обязательна только сеть. Записи в сеть тоже нет.
Собственно всё чем он занимается, это высокоуровнево диктует фиксированный порядок чтений записи/чтения через переданные лямбды. И оповещение всех подписчиков.
Один инстанс DOD работает с одним семантическим ресурсом. Например таблицей или запросом, и поддерживает одновременные стримы одного типа по разным параметрам.
Например два подписчика могут через один DOD следить за объектами с id "1" и "2". Если в следствии нормализации стейта объект "1" поменяется - подписчик по id "1" получит ивент с новой Data.
Прелесть в том, что сам DOD почти ничерта не умеет, кроме собственно организации порядка походов в бд/память/сеть и уведомления об изменениях по параметрам. Но декорации позволяют накрутить поверх лямбд почти любую логику.
Например автоматические ретраи сетевого ресурса подключаются снаружи DOD. Протухание кэша в БД тоже снаружи. Порядок событий остаётся точно такой же.
Ещё параллельно развился целый набор Rx экстеншенов под именно Observable<Data<*>> стримы. Типа .takeUntilLoaded(), skipWhileLoading() итд.
Если кому это показалось интересным: на медиуме есть моя статья по этой либе, с кодом и снипетами
medium.com/revolut/reacti…
Документации там нет, потому что, в целом, использование её мы и не пушим никому. Она больше носит демонстрационный характер, чтобы можно было показать как можно организовывать реактивные стримы из разных источников. А Rx2 или Rx3 там, или вообще корутины не так важно.
У нас к ней ещё в роадмапе списочный аналог. В этом тоже в целом можно обзёрвить сеты и сабсеты данных по параметрам. Но есть пара неочевидностей которые постоянно стреляют в колени всем.
У нас в Революте эта штука показала себя крайне надежно. Она работает больше чем в двух сотнях мест, для всех, без пары исключений, сетевых запросах, в трёх приложениях, на двух разных архитектурах (MVP/ MVVM).
Вторая либа, RecyclerKit, начался с довольно безумной идеи три года назад любой экран делать на ресайклере используя довольно популярный подход адаптер делегатов.
github.com/revolut-mobile…
Причём любой - это вот прям каждый. Даже с 10ю элементами. Это позволило всю нашу дизайн систему базировать по сути на горизонтальных микроайтемах. Любой экран в 99% составлен из горизонтальных блоков. А когда - нет, ну там тож не сложно.
Fast forward 3 years: подход оказался настолько удобен и универсален, что большая часть нашего свеже-переделанной дизайн системы - это делегаты ресайклера.
Собственно RecyclerKit - это коллекция всего что может понадобиться при работе с ресайклером используя его на каждом экране (и ещё пара бесполезных приблуд).
Начинается он с базового класса для каждого элемента списка: ListItem. Не сильно дальновидное название вышло, грид айтемы в целом в целом тоже поддерживаются, но вроде не большая проблема.
Далее идёт Delegates Adapter в модуле delegates, который и занимается регистрацией делегатов для ListItem объектов.
Есть ещё rxdiffadapter. У него есть доп режим работы - async. Он хранит только последний setItems пока высчитывает дифф на computation, и дропает избыточные. Он тащит за собой Rx, но в целом не обязателен. Можно последний ListAdapter использовать. Но он дропать не умеет кажется.
Ещё к этому всему прикручены кастомные ItemAnimators. Они в целом полная копия DefaultItemAnimators из SDK, но позволяющие ViewHolder перехватить и переопределить анимацию некоторых конкретных элементов. У нас всего пара кейсов и они странные, но если очень хочется то можно)
Ещё есть модуль decorations, c кастомными ItemDecorations, которые к стандартному лэйауту элемента могут добавить отступ, тень или оверлей. Тоже работают через ListItem.
Вот эта либо прошла полный круговорот - начавшись с либы адаптер делегатов, в которую вхреначили базовый класс для всех элементов, а потом декораторы. И потом ещё аниматоры которые тоже по ViewHolders работают. Такой компот в целом, сваренный и выложенный обратно)
Пятница
И чуть не забыл про последний артифакт - rxdata.scheduler. Это клон HandlerScheduler aka AndroidScheulers.mainThread() с одним нюансом. Если onNext происходит на mainThread, он ведёт себя как ImmediateScheduler, сразу запуская runnable.
Нужно это потому, что почти что каждый Data стрим нужно в итоге переключать на мейн тред через observeOn(AndroidScheduler.mainThread())
А у DOD в контракте есть первый эмит, который происходит на треде, на котором был вызван subscribe. А все последующие уже на IO.
Но вот этот вот observeOn с дефолтным скедулером заскедулит этот эмит в следующий мессадж лупера. И если DOD прочитал данные синхронно из памяти - презентер их получит не в Activity.onStart | Presenter.onAttach, а чуть позже, что вызовет blank стейт на ровном месте.
Но штука опасненькая, полностью включили её только в особо тяжелых местах и во втором приложении. Сложные стримы с зацикленными ивент лупами могут либо встрять в бесконечный луп, либо вообще потерять эмиты. Но я бы сказал, что это косяк именно стримов, а не скедулинга.
Поговорим ещё немного о TDD. Есть тут те кто пробовал TDD, возможно использует TDD, но периодически ловит себя на мысли что чет не то? Вроде делаешь всё по заветам; публичное одобрение и плюсы в карму при упоминании заветных трёх букв, но вот не в радость.
Вы не одиноки. Начну с того, что часто забывают упомянуть на конференциях и в статьях: когда TDD не работает.
Начну таки с брошюрных плюсов и преимуществ, которые обещает дать TDD:
Более глубокое понимание разработанной сущности, их эдж-кейсов.
Более продуманное API таких сущностей. Когда разработка начинается с написания теста - API занимает первое место, а внутренняя реализация последнее.
Когда стоит писать по TDD? Вы проектируете какую то новую сущность, контракт не продуман. Задача поставлена размыто: "репозиторий должен сообщать об изменениях в базе данных".
Как сообщать, кому сообщать, как это соотносится с недавно заимплеменченным "репозиторий должен сообщать об изменении состояния обновления данных из сети"?
Это два сообщения или одно? Если одно то как выглядит частичное сообщение? На все эти вопросы поможет ответить TDD. Вы пишете тест с позиции будущего юзера этого репозитория. Добавляете нужные кейсы, продумываете контракт.
Когда вы приступите к разработке - контракт будет зафиксирован. Что под капотом тест не волнует - outcome должен оставаться один. Под капотом могут быть очереди событий, или конечный автомат. Тест зелёный вне зависимости от имплементации.
Он помог зафиксировать контракт и быть более спокойным при потенциальном рефакторинге.
Рассмотрим вторую задачу. "Вывести телефон получателя денег в детали транзакции". Получатель денег лежит внутри transaction.details. Вы радостно начинаете с теста, который мокает такую транзакцию.
Тест (предположим у вас есть декларативный абстрактный фрейморк на presentation слое, как у нас кек) проверяет, что в сете ViewItems появился TextItem("phoneNumber", padding = Paddings.Large, style = Style.Phone).
Далее вы приступаете к имплементации, добавляете, код в презентер или в чтоувастам и запускаете аппу. И вьюха появляется, но паддинги не подходят. И вы идете переписывать имплементацию и тест.
Через n-итераций проверки (хорошо если она была одна) и обновлений кода в двух местах, вы гордо коммитите test-driven-developed фичу.
Это, максимально лаконично, Анкл Боб назвал fiddling. Не менее лаконично, я думаю на русский язык такое можно перевести как теребоньканье.
Теребоньканье - по большей мере декларативное взаимодействие с другой, независимой системой (как Android Framework, или любой проприетарный промежуточный фреймворк).
Тут нет ни одного бенефита из первого кейса, вы не продумаете API (по сути тут используется готовый), крайне маловероятно найдете какие-то эджкейсы, и лишь только будете теребонькать в два раза больше.
Анкл Боб вообще изначально говорил про near physical systems и системы, которые требуют верификации человеком, что они действительно работают.
Как более софтверный пример приводился CSS. Почитать можно тут: blog.cleancoder.com/uncle-bob/2014…
Мой совет для таких ситуаций - просто напишите имплементацию, проверьте её в аппе, и зафризте юнит тестом в конце.
Отдельным словом короткий привет тем падаванам TDD которые на малейшие движение курсором в классе начинают гудеть, что пока теста нету, даже курсором в классе двигать не стоит)
Самая главная идея TDD - это короткие итерации. тест-код-тест-код-тест. Главное выработать дисциплину всегда работать со своими сущностями через тесты и двигаться итеративно. А если среди ста итераций первое звено вдруг случайно не тест, а код - мир не рухнет.
Пара слов про тесты в целом. Любой тест, даже написанный после кода, должен оставлять свободу в имплементации.
Если такой свободы нету, и тест 1:1 проверяет код имплементации, польза от него конечно остается, но она стремительно приближается к нулю.
Да, тест, упадет если кто-то поправит ваш кейс, или уберет номер телефона из деталей транзакции окончательно. Шанс что это будет сделано по неаккуратности тоже имеется, но практике ничто не мешает разработчику удалить вместе с кодом и тест на него.
Если же имплементация обобщенная, а тесты конкретны - то участок кода на соответствующий тест даже не всегда замапить получится, не то что удалить вместе с ним. Это добавляет устойчивости кодовой базе в целом.
И ещё немного гвоздей в крышку гроба TDD (неправильного)
TDD Doesn't Work: blog.cleancoder.com/uncle-bob/2016…
TLDR: с одной стороны исследования и мнения, что TDD вообще не работает, а фиксация на юнит тестах породила тысячи монструозных архитектур, с миллионами микросущностей, каждая из которых прям сквозит осторожностью сделать чуть больше и потерять в тестируемости
С другой стороны какая то пост-ирония того-же Анкл Боба, который в формате воображаемого диалога троллит исследователей и, видимо, тех, кто верит таким исследованиям, не читая.
Суббота
Сегодня будет небольшой лишь один лейт найт тред про продуктоунерство, 10x инженеров и всякие внеклассные активности)
Причет тут вообще спросите инженеры?
Инженеры - это вообще один из самых мощных источников технологических и продуктовых инноваций в любой компании. Давать инженерам готовое ТЗ и ждать когда переключат статус в джире - огромная потеря.
И продуктовая компания всегда заинтересована чтобы мы не только код писали, но и разбирались для чего он вообще. Чтобы могли предложить какие то улучшения, разбирались в данных и метриках, чтобы подкрепить их.
Многие компании, кстати, сразу на собесах стараются проверить насколько развит у разработчика product thinking.
Теорию когорт конечно спрашивать не будут, но могут попросить выдвинуть предложение по улучшению апки и представить какие-то метрики для проверки результата.
Лично я, как и многие, подходил к программированию как к довольно инкапсулированной деятельности. Я готов был залипать в различных архитектурах, патернах разработки, библиотеках, абсолютно не вспоминая о чём вообще проект.
Дайте ТЗ. На всё должно быть ТЗ, с расписанными кейсами, я уже буду проектировать как это всё заимплементить, наложить на навигационный фреймворк / мвп архитектуру / реактивную библиотеку
Позиция была, что пусть то хоть соц сеть для хомяков, написание кода, в целом, от этого не меняется, и должно быть одинаково хорошо.
Перелом начался наверное именно в Революте, когда я сам по настоящему начал пользоваться приложением. Первые месяцы это был довольно кастрированный экспириенс, я тогда еще жил в Питере и основным банком был Тиньков.
Но как ток переехал, догфудинг заиграл во всю свою мощь. Догфудинг вообще довольно простая концепция - это просто когда сотрудники пользуются тем, что создают.
Последние полтора года я на проекте Трейдинг, год назад мы его зарелизили, и вот тут догфудинг возвёлся в куб.
Я довольно давно занимаюсь трейдингом, инвестициями и работать на проекте которым ежедневно пользуешься сам эт прям отдельный класс зависимостей.
Мне сразу хотелось предлагать какие-то изменение, топить за фичи и за то, что же делать в первую очередь.
И тут вернёмся к продуктоунерам. Главное отличие хорошего в том, что он включает всю команду в поиск идеального решения. Он не спускает сверху ТЗ, и не говорит КАК сделать. Часто даже не говорит ЧТО. Есть только ДЛЯ ЧЕГО. КАК и ЧТО решает команда.
ПО культивирует в команде peer-to-peer отношения. Это называется enablement. Если вы чувствуете - что дизайнер - ваш босс, и его макет в фигме - это библейские скрижали, в вашей команде, вероятно, что-то не так, она - disabled.
И вот тут разработчик решает для себя, интересен ли ему продукт, и если интересен, принимать участие в том ЧТО и КАК, или нет. И если принял и получается хорошо, то инженер ПО - не такая уж и редкость и крайне ценный кадр в продуктовой компании 😉
А если вас не интересует именно продукт, а только его техническая составляющая - 10x инженер - ваш путь.
И забудьте мифы про разработчиков, которые в 10 раз умней, талантливей или продуктивней.
10x - это про тот же самый enablement, но не продуктовой команды, а инженерной.
Если один разработчик может поднять уровень 10ти другим, помочь им в чем-то разобраться, направить их в нужное русло, или просто предоставить какой то тулинг, который будет делать их продуктивней - это уже 10x инженер.
Но будьте готовы, что такой 10x оч сложно продать. В суровых реалиях крайне распространен миф, что 10x инженер крутит деревья в 10 раз быстрей, знает строчку для фикса по описанию бага, и именно это часто и пытаются проверить на собесах, а потом и трекать внутри компании.
Воскресенье
Ну и последний мой день будем говорить про шкуры неубитых медведей aka фантики aka золотые наручники или по простому опционы. У кого-то они уже есть, кому-то их предлагали, а кому-то предложат в будущем. Начнём с финансовых азов и истории простыми словами.
Публичные и приватные компании ещё со времён Ост-Индской компании просекли, что самый простой способ привлечь наличность в оборот - это краудфандинг.
Ост-Индская компания наверное самый большой "финтех" коллониальной эпохи. Причем Голландская, Британская был унылой копипастой.
Компания занималась судостроением и торговлей в 16 веке. Судостроение штука опасная и рискованная. Корабль могут потопить, корабль может утонуть вполне и без посторонней помощи. Но один вернувшийся корабль окупает десять затонувших.
Чтобы минимизировать операционные риски выпускаются долговые обязательства - кеш берется в долг у населения, в замен даются акции, которые гарантируют пропорциональные дележку прибыли меж всеми участниками.
То есть если вы купили на 100$ акцию компании, было вполне ожидаемое окупить её за три-пять лет. Дальше она начинала приносить чистый доход.
Модель получилась настолько успешным, что в какой то момент Компания перегнала Голландию по капитализации, и денег у неё занимала королевская семья на государственные нужды. Четвертую англо-голландскую войну по сути вели два акционерных сообщества.
FW в 2020: механизмы те же самые, компании продают свои акции публике за деньги, которые идут в оборот и на рост компании.
Разделение прибыли между акционерами называется дивидендами, и многие инвесторы/трейдеры уже забыли, что компании существуют и продают акции, чтобы делиться прибылью. Диведендные инвест портфели уже не такие зеленые как в 16 веке.
Баллом правит рост. Рост экономики, рост капитализации. Если вы покупаете 10 акций Apple, то вряд-ли думаете о 0.98% дивидендов. И о том, что одной акции было бы неплохо окупиться доходностью хотя бы на горизонте 20 лет.
Вы её покупаете, потому что знаете, что Apple растет за год на стабильные 15% в год, и через год эту акцию можно будет продать дороже. За сколько акция окупается уже не так интересно, и прибыльна ли вообще компания масс маркету уже не так интересно.
Есть приватные и публичные компании. Принципиальная разница в том, что публичные компании сильнее зарегулированы, их принуждают публиковать финансовую отчетность. И рядовому гражданину купить получится только публичную компанию, в основном из-за регуляций.
Государства заинтересованы, чтобы для инвестирования были доступны только максимально прозрачные и проверенные активы, с наименьшими рисками.
Ну или чтобы у населения не было доступа к инструментам реального роста, но это из области теорий заговоров.
Чтобы купить акцию приватной компании, придется сильно заморочиться. Нужно быть квалифицированным инвестором, иметь доступ в bloomberg terminal или выход на частных брокеров и располагать довольно большим объемом средств.
Затариться на сто баксов тоже не получится, там вход на несколько порядков выше. Другой вариант - вложиться в ETF который держит частные акции, но будет пакетом идти куча компаний.
Абсолютно не торгующиеся приватные компании скорее исключение, почти в любую компанию привлекаются внешние деньги.
Теперь подходим к более близкой теме - стартапам.
Стартапы это подкатегория частных компаний. У них крайне низкая ликвидность. Компания продаёт свои акции в среднем раз в год-два. Доступ к инвестированию только у профессиональных инвесторов.
Самое первое привлечение капитала называют venture round. Это когда 10 сотрудников, им на какой то рабочий продукт и вывод на рынок надо 100-500 тысяч баксов. В основном кормить себя, снимать офис, минимальная реклама.
Один из этих 10 сотрудников может оказаться мобильный разработчик. И вот тут начинается интересное.
Скажем средне по рынку разработчик стоит 100 тысяч баксов в год. Если он придёт в стартап, и попросит себе честную рыночную зарплату, выдавать ему акции не очень честно по отношению к инвесторам.
Для них купленная акция на этом этапе - это риск потерять вложения. Разработчик ничем не рискует получая рыночную зп.
Второй вариант, это устроиться скажет на 70. И взять акций компании на 30к. Теперь разработчик полноправный инвестор, на равне с инвесторами.
Нюанс тут в том, что инвесторы как правило диверсифицированы, и их риски полностью прогореть сильно ниже. Разработчик не диверсифицирован. Этот момент пока просто запомним.
Теперь у разработчика есть 30 "акций" компаний. Почему в кавычках? Потому что выдают их опционами.
Не получилось нагуглить, что появилось раньше - опционы как торговый дериватив, либо опционы которые выдают топ менеджменту компаний, но технически, это просто финансовый инструмент, который позволяет минимизировать потери при падении актива.
В трейдинге можно купить 10 акций эпл, и если они упадут на 20% - потерять эти 20 процентов. А можно купить опцион на 10 акций, и реализовать его только если вырастут. Если упадут - потеряется только фиксированный премиум, стоимость самого опциона.
Почти то же самое тут. Только опцион чаще всего бесплатный. Его просто можно "to exercise" если компания выросла в цене, либо забыть как сон с Ламборгини, если компания разорилась.
Предположим компания X вам прислала оффер, в котором говорит, что вам при принятии выпишут опционов на 100к долларов. Давайте посмотрим что это может значить.
Вопреки странным советам бизнес коучей, какой процент от компании составляет данный опцион информация довольно бесполезная. Вы же не задумываетесь сколько процентов компании составляют ваши 10 акций Apple? Вот и тут не надо.
Это может интересовать наверное только потенциально голосующих инвесторов, которые желают принимать участие в собраниях совета директоров и иметь там какой то вес. Остальным нужно знать только два числа: exercise price, и текущий stock price.
Вообще в случае деривативов, это должно быть одно и то же число. Но в мире стартапов это часто не так.
Exercise price - это стоимость, которую нужно будет заплатить за каждую акцию в опционе. stock price - это реальная цена реальной продажи акции. Разные они потому, что первую диктуют налоговые/регуляторы, вторую инвесторы которые непосредственно покупают акции.
Положим в примере выше, stock price = 1$. Вы являетесь счастливым обладателем опциона на 100к акций. Теперь, если exercise price равен 1$, то чтобы реализовать опцион - вам нужно заплатить 100k$. Делать это выгодно только в случае если компания уже выросла, предположим в 2 раза.
Тогда ваш профит - это 100к$. Если компания стагнирует или падает - вы не делаете ничего. Технически, если на каком-то из этапов вы согласились просесть под рыночную зарплату - вы прогорели именно на разницу с рынком в зарплате.
Но, есть схемы, когда exercise прайс не равен stock price. Для примера выше, он мог бы быть 0.01$. Тогда для реализации вам нужно заплатить всего лишь 100$. И после этого продать за 100k$.
В таком сценарии математика гораздо более приятная и оказаться в плюсе шансов сильно больше.
И теперь о ликвидности. Во многом именно ликвидность будет определять, заработаете вы на опционе или нет.
После venture round - есть еще много раундов, когда компания допривлекает кэш. Им дают буквенное обозначение, и доходят они до примерно 5й буквы в алфавите. Round A-B-C-D-E
Ликвидность в контексте - это именно возможность в них поучаствовать, но как и во всём тут есть нюансы. Не всегда компания может дать полностью реализовать сотрудникам имеющиеся опционы по следующей причине.
Предположим мы на раунде B, и компанию оценивают в 500 миллионов, x2 относительно предыдущих 250. x2 кстати не редкость между A-E раундами
Раунд и переоценка означает очень грубо три момента. 1. Компания довыпустит акций. 2. Эти акции купят по новой цене за кеш. 3. весь веш пойдет в развитие.
И вот стафф выводящий опционы, по сути, залазит в суплай всех инвестиций. То есть деньги идут не в развитие, а на вывод. А это может составить довольно большую долю, если многие разом решат повыводить свои мильоны.
И тут, наверное, есть какая то общепринятая цифра, какую можно отдать на нужды именно выкупа стоков у сотрудников. Какая именно не знаю, но скажем 5%. И эти 5% - они не от всей разницы новая/старая капитализации.
Когда компания при оценке в 250 на раунде увеличивает капитализацию до 500, это не значит, что кэша именно 250 миллионов. Это запросто может быть и 50, просто инвесторы согласились, что эти 50 будут именно по новой цене соответствующей капу в 500кк.
Так вот 5% от гораздо меньшей суммы. Даже если от 50% - то это 6.25kk. А на момент таких раундов у компании уже может быть сотни сотрудников. А это хорошо если по паре десятков тысяч на человека.
И вот только если компания заморочится, она может провести дополнительный peer-to-peer раунд для более маленьких инвесторов. Особенность вышеописанного раунда в том, что туда пускают не только лишь всех.
А вот на дополнительном, более мелком раунде, если есть деманд среди более мелких инвесторов, можно организовать продажу с гораздо меньшим ограничением ликвидности. И делает так компания или нет - это тоже очень важный момент, который стоит выяснять.
Выяснять можно просто спросив HR. А можно провести ресерч по истории продаж. Эта информация во многих странах полностью публичная, хоть и с существенной задержкой.
Это очень важно, потому что часто возможность вывести в нужный момент гораздо важней чем рост, который может и легко развернуться в обратную сторону. Потому что такие компании в целом чаще растут, чем нет, вплоть до самого последнего момента краха.
Понедельник
Ну и пару общих слов. Я вообще считаю, что опционы в глобальном смысле, очень хороший инструмент профит шейринга для компаний. А профит шейринг - это вообще крайне полезная штука для глобальной экономики и инвестиционного климата.
Когда в успешной компании 1 человек становится миллиардером, ему очень легко сделать сотню другую людей миллионерами, из которых многие пойдут на этот капитал делать другие проекты, и, может, единицы повторят этот круг.
Только нужно отчетливо понимать, как это всё работает, и чем вы рискуете. Вспоминая проседание под рынок ради опционов - это на самом деле не сильно частое явление. Чаще всего зарплата остается рыночной. Кроме самых первых может этапов, где и риски и профит выше.
И получается, что рисковать, соглашаясь на опционы одной компании, приходится чаще всего только возможностью получить опционы другой.
И возвращаясь к профит шейрингу. Это один из главных факторов того, что сделало Кремниевую Долину эпицентром стартап мира. И в целом, я наблюдаю, что стартап климат в Европе и UK начинает в этом плане разогреваться.
Есть уже целые компании, которые предоставляют услуги трекинга стоков и опционов, типа Carta. Есть компании, которые трекают стартапы, их стоимость и раунды, типа Crunchbase. Есть поисковики вакансий с акцентом на equities и shares типа Angel List.
В многих Европейских государствах лобируется схемы облегчающие налоги на опционы. И различные схемы протекции держателей.
И вот еще хорошая статья подобные схемы помогают генерировать благосостояние экономики. bloomberg.com/news/features/…
Ну вот и всё) Спасибо всем, кто читал и отвечал)
С вами был @yatsinar, если кому интересно почитать про стартап инсайды, Лондон и разработку - то в моём твиттере этого нет лол. Но если вырвусь из замкнутого лупа "нет подписчиков - не пишу - нет подписчиков " то может будет)








