Архив недели @eugene_kr
Понедельник
Всем привет!
На этой неделе с вами я, Евгений Кривобоков (@eugene_kr).
#НоваяАватарка #АвторНедели #день1из7
Начнем неделю. Сегодня расскажу про сборку приложения.
Будет много капитанства, но это стоит проговорить для полноты картины. #день1из7
Начать хорошо бы с официальных рекомендаций
- developer.android.com/studio/build/o…
- guides.gradle.org/performance/
Они обновляются под новые версии. Если давно не заглядывали, то самое время освежить.
Используем последние версии AGP, Gradle и всех тулзов с кодогенерацией.
Насколько свежие? Выбираем подходящий для команды баланс между стабильностью и новыми фичами.
Вчитываемся в changelog и пробуем.
"Сделать ли мне "Х", ускорит ли сборку?" - на такой вопрос нет однозначного и простого ответа.
Это гипотеза. Чтобы ее проверить, надо представлять как это работает внутри. Чем лучше мы понимаем внутренности работы, тем более эффективные модели получается строить.
А что собственно ускоряем? Надо найти где болит и научиться это измерять. Используем github.com/gradle/gradle-….
Сценарии должны отражать типовые изменения в проекте и покрывать оптимизации в системе сборки (изменение ABI, инкрементальность, чистые сборки и т.п.).
Такие проверки дорогие, поэтому запускаем их уже в develop. Это дает понимание трендов и ловит только очень крупные изменения.
Основная ценность готовых сценариев в другом. Мы упрощаем себе проверку подозрительных изменений, которые влияют на сборку.
Выносим сборку на более мощную машину: github.com/Instamotor-Lab…
Для мелких изменений иногда медленнее получается, дольше ждем синхронизацию файлов.
Также при изменении структуры модулей может сломать модели проекта для IDE, приходится все чистить.
В целом есть смысл пробовать.
Для поиска узких мест - build scan scans.gradle.com. Визуализация решает, да и типовые проблемы подсвечивают явно.
Большую часть информации можно достать самостоятельно, через API. Завтра про это подробнее.
Свежее видео с Droidcon Berlin 2019: droidcon.com/media-detail?v…
Новый день - новые баги. А ведь только похвалил build scan. Говорят, что слишком много данных засылаем. Видимо это толстый намек на покупку Gradle enterprise.

Пару слов про remote cache. Его легко настроить, но все веселье начинается потом. Хорошо если есть Gradle enterpise и он покажет корень проблемы. Но если нет, нужно самому искать.
RTFM: guides.gradle.org/using-build-ca…. С большинством описанных проблем уже столкнулись. А сейчас примеры:
Прогреваем remote cache на linux (docker) и в OSX, потому что есть баги с переносимостью кеша между ОС (issuetracker.google.com/issues/1267752…)
Написали гит хук, который подчищает пустые директории. Ломалось кеширование после рефакторинга (youtrack.jetbrains.com/issue/KT-27687)
Как одна оптимизация ломает другую или еще один пример, почему не стоит их включать без проверки (youtrack.jetbrains.com/issue/KT-31511)
Вручную проверяем параметры окружения, версию build tools, не можем зафиксировать (issuetracker.google.com/issues/1177897…). Это тоже нужно для переиспользования кеша.
И мой любимчик в номинации "веселой отладки, неудачники" thoeni.io/post/macos-sie…
Вот такие трудовые будни. Надеюсь удалось передать почему простые советы плохо работают и нужно разбираться в причинах.
Просто обязан упомянуть замечательный выпуск @PodlodkaPodcast c @artem_zin : podlodka.tilda.ws/87
Сразу огворюсь, с bazel мало знаком, не могу по существу сравнивать. Затронем еще эту тему при обсуждении CI.
Вторник
Сегодня поговорим про метрики сборки и их мониторинг #день2из7
Собирать данные конечно нужно со всех машин, потому что окружение отличается. К счастью, есть готовые бесплатные решения:
- github.com/cdsap/Talaiot
- github.com/nebula-plugins…
Даже если и решите написать свое, это отличные примеры как добраться до нужных данных.
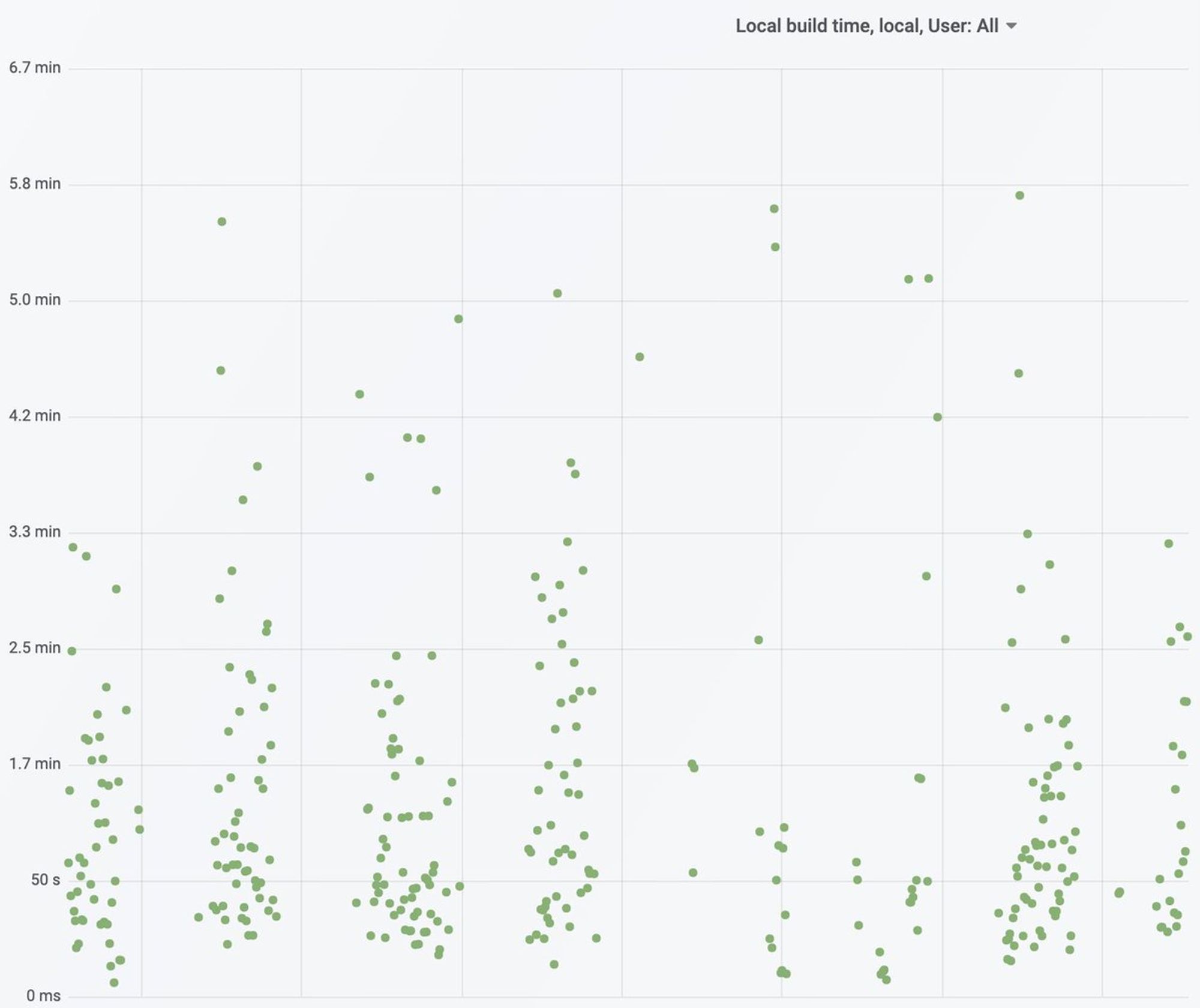
У нас свое решение, на порядок упрощенный аналог Talaoit. Из важных показателей:
- Общее время сборки
- Время конфигурации
- Медленные задачи
- Кешируемость* задач
(ставьте лайки - github.com/gradle/gradle/…)
Хороший подход - как в build scan, хранить сырые данные по каждой сборке и по ним уже строить агрегаты.
95 перцентиль
Мы любим fail-fast подход.
Если нашли причину performance деградации и можем ее проверить автоматически, то добавляем в сборку.
Например, если попытаться собрать проект с неподдерживаемой версией Java, то сборка сразу упадет с пояснением причины. Так зачастую дешевле и понятнее.
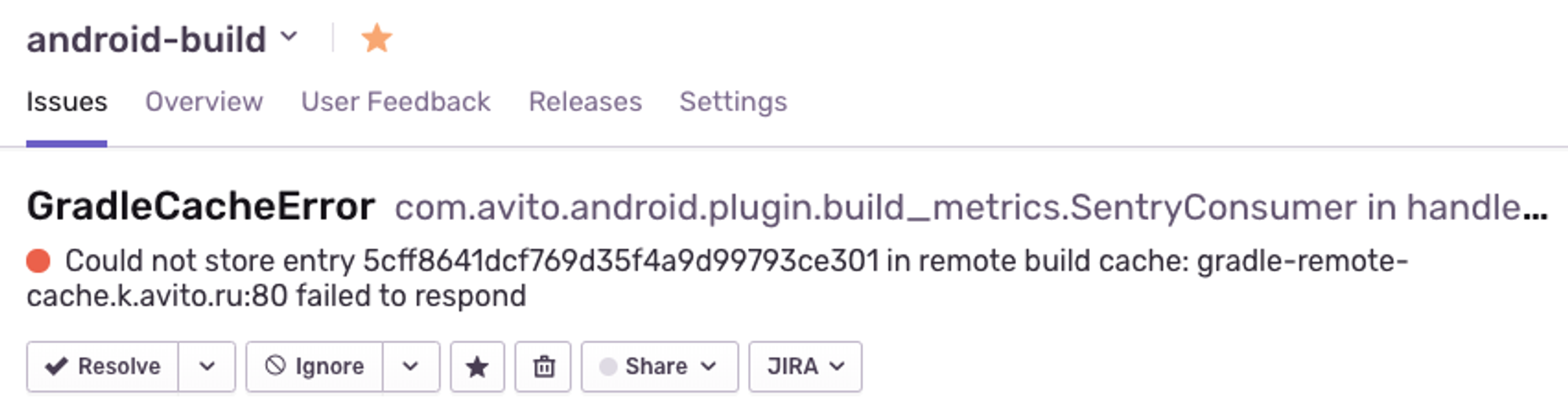
Все ошибки сборки перенаправляем в Sentry.
Инструмент как раз под такую модель данных - stacktrace и параметры окружения.
Среда
Сегодня про Android Studio :harold:
#день3из7
Какую IDE используете под android?
Как можем повлиять на IDE?
Как минимум, отключаем все что только можно.
Собрал все что нашли: gist.github.com/eugene-krivobo…
Когда смотрите время исполнения gradle задач, помните что оно может быть завышено для worker api (github.com/gradle/gradle/…). В AGP 3.5 уже перевели большинство задач (android.enableWorkers).
Помогает другой профайлер - android.enableProfileJson, который показывали на Google IO.
Узнал лимит для бесплатной версии: 5242880
Несмотря на Project Marble, AS все еще тормозит как не в себя, особенно в тестах. Мы подумали, что могут быть специфичные проблемы в нашем проекте. Стали проверять разные гипотезы на тестовом проекте. Пример генератора, чтобы с нуля не начинать: github.com/android/androi…
На тестовых проектах все отлично, как бы ни пытались их усложнять. Были разные гипотезы: количество модулей, какие-то фичи языка, тяжелые инспекции, lint проверки и т.п. Ничего из этого не получилось достоверно подтвердить.
Пока подтвердилось очевидное: размер classpath.
Если модулю доступно много классов, это негативно влияет.
Пример бага на эту тему: issuetracker.google.com/issues/1331242…
Когда все плохо и AS не справляется с крупными изменениями в проекте (mirakle в пример), либо реимпортируем проект, либо вручную чистим .iml модели.
Например, вот так: git.io/fjxI1
(скрипт в стиле дешево и сердито, только ради примера)
Если синхронизация проекта не прошла успешно, то AS может запустить совсем не ту задачу, которая указана в конфигурации.
Проверить можно во вкладке Build | Build Output. В начале лога будет Executing tasks: [assemble]. Без конкретного модуля, значит запустит все с таким именем.
Достали сообщения "WARNING: The option setting '...' is experimental and unsupported."? На каждый модуль?!
Отключаем с помощью android.suppressUnsupportedOptionWarnings.
И голосуем про похожий шум в котлин плагине: youtrack.jetbrains.com/issue/KT-33065
Четверг
Поговорим про жизнь маленького коммита в CI
#день4из7
Пару лет назад наш CI был очень простой. Мы смотрели на опыт других компаний. Здесь хочу упомянуть старую и все еще полезную публикацию от facebook: research.fb.com/publications/c…
В итоге многое вышло довольно похожим.
По мере роста команды и с жаркими спорами пришли к trunk based модели ветвления. Хорошо масштабируется.
Качественный обзор: trunkbaseddevelopment.com
После такого даже нечего добавить.
По верхам про инфаструктуру.
Все android приложения живут в монорепозитории. Любой исполняемый в CI код - в docker, все это крутится в kubernetes. Для CI используем TeamCity.
Все изменения проходят через pull request'ы.
Задача CI - обеспечить "стабильный" trunk. Соответственно, набор проверок подбираем сравнивая их стоимость и закрываемые риски. Универсальных рецептов нет.
Запускаем:
- Юнит тесты
- UI тесты (e2e в том числе). Завтра про это.
- Lint
Юнит теcты не параллелим. Нет необходимости, потому что модули уже довольно мелкие и хорошо параллелится на этом уровне.
Также юнит тесты хорошо кешируются в gradle. Еще один довод в пользу remote cache.
lint гонять по всем модулям нет смысла, дает ложно-положительные ошибки.
Поэтому выгоднее только по приложениям, но с зависимостями checkDependencies (в lintOptions).
Если lint слишком медленный, попробуйте настройки:
- checkGeneratedSources
- checkTestSources
- ignoreTestSources
- checkReleaseBuilds
Подробнее почитать про борьбу за performance и медленные проверки можно здесь:
groups.google.com/forum/#!topic/…
Чтобы сократить объем проверок, в тестировании есть практика impact analysis. Ее можно автоматизировать для тестов.
Описание концепции: martinfowler.com/articles/rise-…
Для android тестов, в привязке к модулям: youtu.be/EBO2S9qcp0s?t=…
Важная концепция - IaC (en.wikipedia.org/wiki/Infrastru…)
CI - это не инфраструктура "сбоку", это часть проекта.
Все изменения - через PR, версии не разъезжаются, сборки получаются более воспроизводимые.
Всю логику CI пишем в Gradle плагинах.
Получаем готовое решение для:
- Построение графа исполняемых задач и его эффективная параллелизация
- Кеширование
- Явно описаны input/output
- Инфраструктура для тестирования
- Доступна полная модель проекта (модули)
- Под JVM (Kotlin)
Плагины покрываем интеграционными тестами (docs.gradle.org/current/usergu…).
Как это выглядит:
Генерируем в тесте git репозиторий с небольшим многомодульным проектом. К нему применяем плагин, кусочек CI. Прогоняем разные сценарии. Зачастую даже удается test first применять.
Любопытная задача: как держать в монорепозитории тесты, которые проверяют этот же репозиторий, целиком?
Для этого в тесте копируем репозиторий, и натравливаем на копию Gradle Tooling API (docs.gradle.org/current/usergu…).
Позволяет снаружи получить модель проекта и позапускать задачи.
У каждой автоматизации своя цена, порой высокая. Мы не умеем проверять в PR абсолютно все инфраструктурные изменения.
Для этого есть чеклисты с тем, что не забыть при изменения в критичных частях.
Большинство пунктов - запускаешь проверки вручную, глазами оцениваем результаты.
Часть проверок слишко дорогие для PR, никакого железа не хватит.
Например, e2e тесты на разных версиях SDK.
Запускаем все проверки после слияния в develop, некоторые вообще только ночью.
Утром команды разбирают найденные баги, чтобы поправить их до релиза.
CD тоже затрону. Уже несколько месяцев делаем canary релизы в android.
Чередуем: одна неделя - полный регресс, другая - катим после авто-тестов.
Теперь изменения доезжают в среднем на 5 дней быстрее. Чтобы не пострадало качество, пытаемся сравнивать метрики между релизами.
До полной автоматизации еще далеко, все равно приходится приглядывать за метриками и крешами.
Но даже если canary релиз остановлен из-за багов, обратная связь от него все равно полезна. Находим проблемы раньше.
И на команду меньше давления, если не успели, через неделю доедет.
Пятница
Продолжаем про CI, сфокусируемся на UI тестах #день5из7
UI тесты пишут все, кто коммитит в код приложений. Для команды это только один из инструментов, как обеспечить необходимое качество и скорость разработки.
Отличный обзорный доклад про это: youtu.be/25EO8E3DMPw
github.com/avito-tech/and… - наша обертка над espresso.
Пишу не с таким посылом, чтобы все пользовались, а чтобы заинтересовать вас проблемами в espresso. Сталкиваемся с ними даже в самых простых действиях, что делает тесты нестабильными. Защищаемся тремя слоями синей изоленты.
Главная проблема с e2e тестами - стабильность. Любая проблема в сервисах сказывается на тестах.
Перезапуски теста сами по себе не помогают.
Ключевая идея: сравнивать результаты прогона на feature ветке и в trunk. Только после этого смогли сделать UI тесты блокирующими в PR.

Метафора: нестабильность инфраструктуры размениваем на время проверок.
Абсолютно стабильные e2e тесты - это недостижимый идеал.
Их задача в PR: убедиться что наши изменения не сделали хуже. Иначе мы просто остановим разработку из-за проблем в любом сервисе.
Поэтому оставляем сценарии, когда может просочиться нестабильное.
Выбрали такой баланс.
А вот так тесты запускаются в CI

Это пример подхода, когда клиент резервирует и управляет эмуляторами.
Альтернатива - общая очередь. Эффективнее, но сложнее и более хрупко.
Коллеги для iOS написали такую очередь - emcee: git.io/fjxDr
Суббота
Хотели бы больше делиться решениями по инфраструктуре.
Считаем что нам это будет только в плюс.
Осталось найти время и удобные форматы.
Смотрели на git.io/fjxu9 - громоздко, удорожает изменения и не факт что переиспользуемо.
Посоветуйте хорошие примеры и практики
На выходные оставил легкую тему, про branch by abstraction #день6из7
Заезженная и очевидная тема. Тем не менее, решил рассказать, потому что в последнее время спрашивали.
Эта практика одна из основных, которая помогла сократить время релиза с месяцев до недель. Необходимая, но конечно не достаточная.
martinfowler.com/articles/featu…
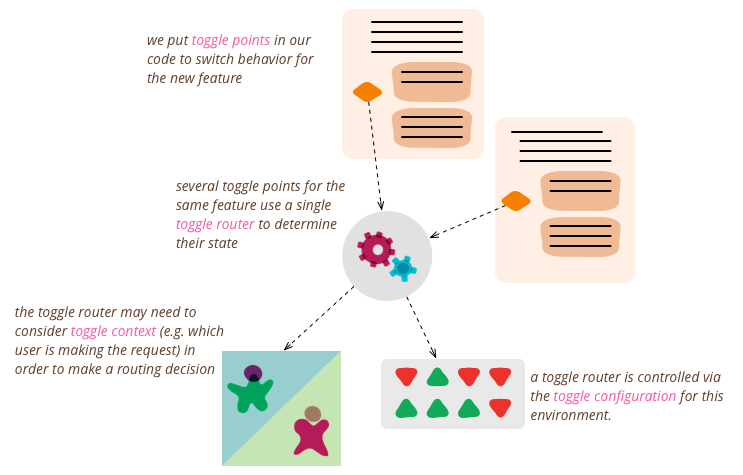
Обязаны ли команды использовать тоглы?
Нет, это не самоцель.
Задача следующая: нестабильная фича не должна блокировать релиз.
Теперь каждое изменение закрывать тоглом? Даже мелкий bugfix?
Решение за командой. По опыту, лучше закрыть тоглом, даже bugfix. Особенно если его тяжело воспроизвести или исправляешь в спешке.
Все ли можно закрыть тоглом? Нет.
Если в compile time меняем что-то, получим другой бинарник на выходе. В runtime уже не поменять.
Если слишком дорого, тоже можем принять риск и катить без тогла.
Некоторые фичи в инфраструктуре тоже закрываем тоглами.
В отличие от приложений, не так критично, можем быстро перевыкатить изменения.
Призываю только к более явным решениям в коде (IaC). Не раз были баги из-за неожиданных environment переменных.
Пример заботы о пользователях, который кажется в AGP встречал.
- В продукте удален deprecated тогл
- Пытаемся его использовать
- Это детектируется и сообщается, что тогл уже не поддерживается, какие есть альтернативы.
Обзорный доклад про то, как пришли к этому, как используем, и про свое решение для удаленного управления.
Не смотрите что про iOS, почти все совпадает.
youtu.be/wxB6Vzo_Xzc
Считаю ошибкой, что сделали отдельное решение для удаленного управление тоглами, не смогли объединить с сплит-тестами. Это должен быть один продукт, во всех смыслах.
Воскресенье
"Лучше работать завтра, чем сегодня!"
#день7из7
5 сентября будет ровно 5 лет, как я работаю в Авито.
Пришел вторым android разработчиком, еще совсем зеленым.
За это время многое изменилось, да и компания стала другой.
Как и зачем работать в одной компании 5 лет?
У меня нет ответа для всех. Упомяну лишь пару идей. Не воспринимайте их за абсолют.
Необходимо менять проекты, технологии, зоны ответственности. Заниматься чем-то одним рано или поздно надоест, каким-бы интересным это не было.
За последние пару лет перестал писать продуктовый код, ознакомился с разными технологиями, попробовал себя в роли тимлида и вернулся.
Коллега поделился: если в компании тебе никто умышленно не противодействует, то все ограничения только в тебе.
Звучит претенциозно, но часто встречал обратную ситуацию, когда была возможность влиять и делать, но искали оправдания, перекладывали ответственность.
А что вы писали запоминающегося в рабочие чаты?
Расскажу про свое хобби - rope-jumping
Что мне это дает:
- Массу воспоминаний
- Знакомлюсь с удивительными людьми, с которыми вряд ли бы с ними вообще встретился в иных обстоятельствах
- Возможность побывать в уникальных местах

10 != 11
26 октября 2018 прилетел в Амман на прыжки, долго не мог понять, почему никого нет и рейсы какие-то странные.
Оказалось, что перепутал месяц и все прилетают 26 ноября.
Интересно было наблюдать за собой в миниатюре фазы отрицания, гнева, ...
И такое бывает
С вами интересно, мне понравилось, но пора передавать эстафету.
Спасибо @igrekde за приглашение!
Остаёмся на связи.
telegram: @ekrivobokov
Понедельник
С вами на линии @igrekde с минуткой рекламы – ведь что может быть лучше утром в понедельник!
В московский офис Indriver открыты вакансии синьора и мидла айосера. У ребят 29млн пользователей и супер интересные задачи, которые делают жизнь этих людей лучше.
За подробностями – sakhayaana в Телеграме.
hh.ru/vacancy/329245…
И пора брать билеты на осенний @AppsConfRussia – конфу, которая помогает мобильным разработчикам расти.
И там можно будет вживую послушать многих авторов этого твиттера, например: @0leGG @nekdenis @ZiminAlex @M0rtyMerr @posipov @sboishtyan